







What Really is Vector Embeddings?
Have you ever wondered how apps like Netflix or Spotify seem to know you so well? They recommend shows and songs that fit your mood almost perfectly, often before you even realize what you’re in the mood for. At the heart of this seemingly magical ability lies a powerful concept called vector embeddings.
Vector embeddings allow machines to translate complex human preferences, ideas, and even emotions into a mathematical form they can understand. These representations aren’t just about storing data—they’re about capturing relationships, similarities, and meaning, helping AI systems make decisions that feel surprisingly intuitive.
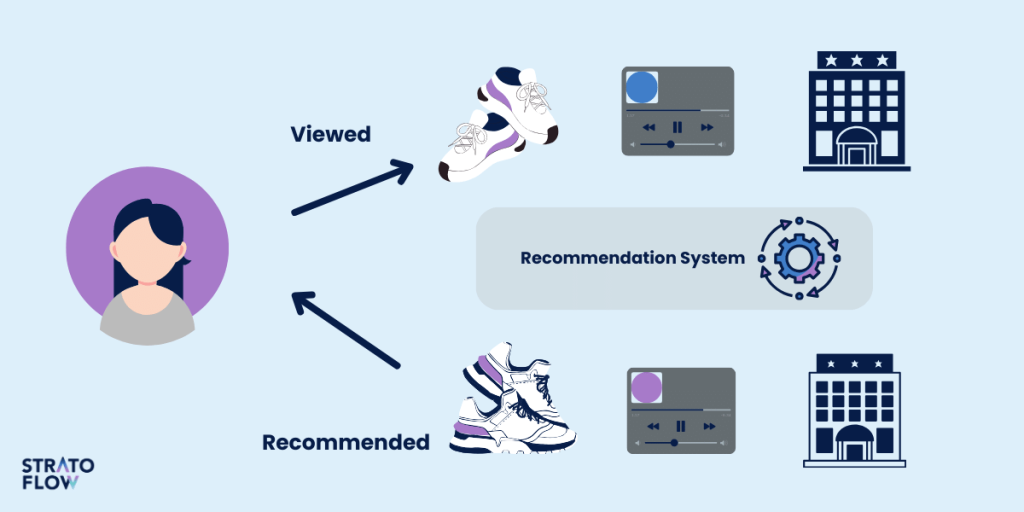
Image credit: https://stratoflow.com/movie-recommendation-system/
As shown in this image, recommendation systems like Netflix’s understand your mood and preferences by leveraging the technology of vector embeddings.
By the end of this blog, you’ll not only understand what vector embeddings are but also discover how they work and how they power everything from smarter searches to personalized recommendations. You’ll even learn how to implement them yourself, opening doors to building smarter applications and exploring the endless possibilities this technology offers.
What Are Vector Embeddings?
So, what exactly are vector embeddings, and how do they make all this possible? In simple terms, vector embeddings are a way of converting data—whether it’s words, images, or user behaviors—into numbers that capture their underlying meaning. These numbers, called vectors, represent a point in a multi-dimensional space, where similar things are grouped together.
For instance, imagine trying to represent the words “dog” and “puppy.” Even though they are distinct words, their meanings are closely related, so their vector embeddings would be located near each other in this space. On the other hand, “dog” and “car” would have embeddings that are far apart, since they’re conceptually different.
The visualization below highlights how embeddings position semantically related words, such as ‘dog’ and ‘puppy,’ near each other.
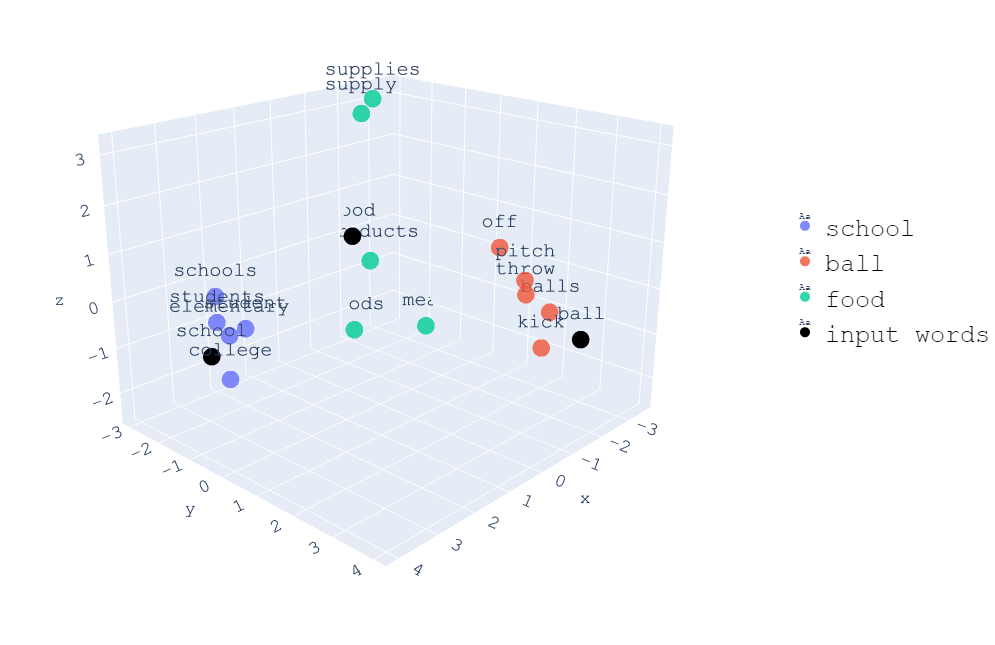
Image Credit: https://towardsdatascience.com/visualizing-word-embedding-with-pca-and-t-sne-961a692509f5
In essence, embeddings allow machines to understand and quantify relationships between data points—whether it’s understanding the connection between words in a sentence, recommending a similar song, or identifying patterns in vast amounts of information.
Now that you have a general idea of what they are, let’s take a deeper look at how these embeddings actually work.
How Do Vector Embeddings Work?
Now that we have a basic understanding of what vector embeddings are, let’s explore how they actually function behind the scenes. To make sense of them, think of an embedding as a map—one that transforms words, images, or even users into coordinates in a vast, multi-dimensional space.
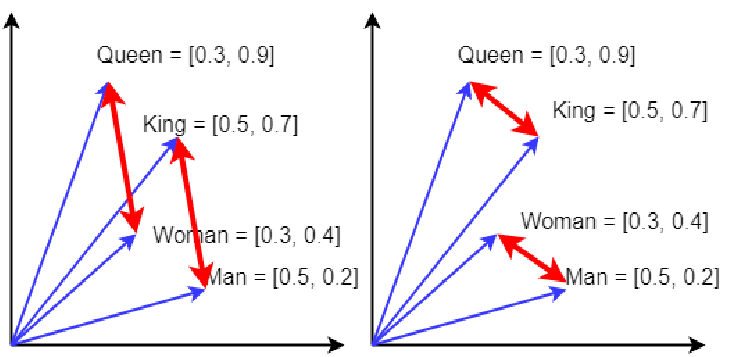
Image credit: https://courses.cs.washington.edu/courses/cse447/23wi/assets/slides/13-NeuralNetworksI-UndergradNLP-2023wi.pdf
In the figure, you can observe how vector arithmetic captures semantic relationships.When you create an embedding, you’re essentially training a machine to recognize patterns and relationships. Here’s a simplified breakdown of how it works:
- Data Representation: The first step is turning the data (like text, images, or user interactions) into numerical representations. For words, models like Word2Vec or GloVe analyze vast amounts of text to understand how words are used in different contexts. The more often two words appear in similar contexts, the closer their embeddings will be in this multi-dimensional space. So, the words “dog” and “puppy” would end up near each other, because they often appear in similar contexts, such as discussions about pets or animals.
- Learning Relationships: The magic happens when the machine starts to learn relationships between these data points. Through training, the model learns which data points are similar and which are different, adjusting the coordinates accordingly. This process continues until the embeddings accurately reflect real-world relationships. For instance, “man” and “woman” might have similar embeddings, but there could be a clear, measurable difference that reflects the relationship between gendered terms.
- Vector Operations: Once we have these embeddings, we can perform mathematical operations on them to explore their relationships further. For example, the difference between the word vectors for “king” and “queen” is very similar to the difference between “man” and “woman.” This means you could use simple vector math to answer questions like, “What’s the female counterpart to ‘king’?” by subtracting the “man” vector from the “king” vector and adding the “woman” vector. The result is the vector for “queen.”
In short, these embeddings allow machines to understand data not just as individual points but in terms of relationships, much like how we process ideas and concepts in the real world.
Some Existing Services and Their Diversified Applications
Now that we’ve explored how vector embeddings work, let’s shift focus to how this foundational technology powers some of the most innovative services and applications. From enhancing search engines to personalizing recommendations, vector embeddings provide the infrastructure that makes modern digital experiences intuitive and efficient.
Service: Embedding-Based Search
One of the most impactful uses of vector embeddings is in powering embedding-based search systems, which go beyond traditional keyword matching to understand the intent and meaning behind queries. At the core of this system is a mechanism that converts both queries and data (like documents or images) into embeddings. These embeddings are then compared in a multi-dimensional space to identify the closest matches based on their semantic similarity.
The screenshot below illustrates how Google’s embedding-based search aligns results with the query’s intent rather than exact keywords.
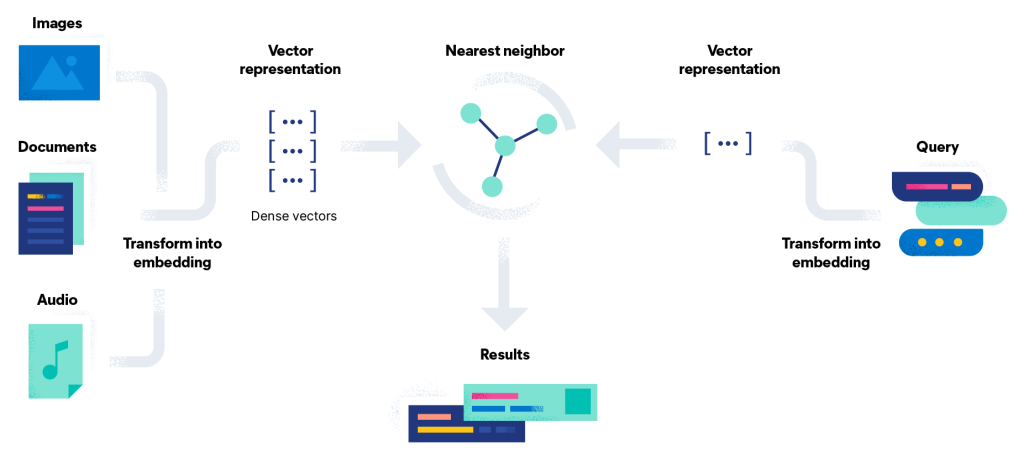
Image Credit: https://www.linkedin.com/pulse/decoding-vector-embeddings-empowering-ai-data-phaneendra-kumar-namala-ngmae/
Application: Google Search
Google’s search engine exemplifies embedding-based search at scale. When you type in a query like, “best places for winter vacations,” the system doesn’t just match these words to web pages containing them. Instead, it uses vector embeddings to understand your intent and retrieve results related to winter travel, destinations, and recommendations—even if those exact terms aren’t present in the content.
A similar approach is used in YouTube’s recommendation engine, which relies on embeddings to match a user’s viewing history with videos that share similar themes or patterns, ensuring suggestions are contextually relevant.
Service: Collaborative Filtering with Embeddings
Another service where embeddings shine is collaborative filtering, a technique used in recommendation systems. Instead of relying solely on predefined categories (e.g., “action movies”), collaborative filtering uses embeddings to map user preferences and content features into the same space. This allows systems to identify patterns and recommend items that align with a user’s unique tastes.
Application: Spotify’s Personalized Playlists
Spotify’s recommendation system, particularly its Discover Weekly feature, is a stellar example of collaborative filtering powered by embeddings. By analyzing what users listen to, skipping or saving songs, and even the musical features (e.g., tempo, genre) of tracks, Spotify creates embeddings that capture both user preferences and song characteristics. These embeddings are then matched to suggest tracks you’ve never heard but are likely to enjoy.
This same approach underpins platforms like Netflix, where embeddings map user watch history and movie characteristics to suggest titles that align with viewing habits. For instance, if you binge romantic comedies with an adventurous twist, Netflix might recommend a film that shares a similar narrative structure, even if it’s not categorized explicitly as a rom-com.
Applications of Vector Embeddings
Having explored how vector embeddings power some of the most innovative services today, let’s now dive deeper into their broader applications. Beyond search engines and recommendation systems, these embeddings unlock potential across numerous industries and use cases. Here’s how:
Semantic Search: A Smarter Way to Find Information
Traditional keyword-based searches have limitations—they often rely on exact matches and struggle to understand context. Vector embeddings, on the other hand, interpret the meaning behind your query and retrieve results that align with it.
For instance, in semantic search, a query like “affordable apartments near downtown” doesn’t just look for pages containing those exact words. Instead, it matches the query’s intent with relevant content, such as listings for “low-cost housing close to the city center.” This application is invaluable in industries ranging from real estate platforms to academic research databases.
Recommendation Systems: Beyond the Obvious
While platforms like Netflix and Spotify have demonstrated the power of embeddings for entertainment recommendations, their applications go far beyond media. E-commerce platforms like Amazon use embeddings to analyze purchase histories, browsing patterns, and even customer reviews, mapping all this data into a shared space. This enables hyper-personalized recommendations, such as suggesting products based on not just your preferences but those of users with similar behavior.
Similarly, in online learning platforms like Coursera, embeddings pair students with courses or materials that fit their learning paths. If a student excels in basic programming but struggles with algorithms, embeddings guide the system to recommend tutorials or courses that strengthen those weaker areas.
Anomaly Detection: Finding What Doesn’t Belong
Anomaly detection is critical in sectors like cybersecurity, finance, and healthcare. By mapping “normal” data patterns into an embedding space, systems can detect outliers—data points that don’t conform to expected patterns.
For example:
- Finance: Embeddings analyze transaction behaviors to flag fraudulent activity, such as sudden, unusual purchases.
- Healthcare: Patient data is mapped into embeddings to detect anomalies, like unexpected test results, which could signal early signs of disease.
Clustering and Classification: Organizing Complex Data
Vector embeddings make it easier to group similar data points and classify them based on shared features. This is particularly useful in large-scale datasets where manual organization is impossible.
For instance:
- Customer Segmentation: Businesses use embeddings to group customers by purchasing habits, enabling more targeted marketing campaigns.
- Content Organization: Platforms like YouTube group videos into clusters based on shared themes, making it easier to organize and recommend content.
Cross-Modal Applications: Bridging Text, Images, and More
One of the most exciting uses of embeddings is their ability to connect different types of data. Cross-modal embeddings allow systems to map text, images, and even audio into a shared space.
Applications include:
- Image Search with Text: Platforms like Pinterest let users search for images using descriptive text. The embeddings translate the query into a space where images with similar features can be retrieved.
- Video Captioning: Embeddings enable AI to generate descriptive captions for videos by bridging the visual content with language data.
These applications demonstrate the versatility of vector embeddings, making them indispensable across domains. Up next, we’ll take this exploration further with a practical implementation example, showing you how to apply embeddings to build your own semantic search tool.
Implementation Example
Now that we’ve seen the versatility of vector embeddings across various applications, it’s time to shift gears and get hands-on. Let’s explore how to use vector embeddings to build a semantic search tool—one of the most impactful and widely used implementations of this technology.
Semantic search goes beyond simple keyword matching, leveraging embeddings to understand the intent and context of a query. For instance, if you search for “affordable apartments near downtown,” the system can retrieve listings like “low-cost housing in the city center,” even if the exact words don’t match.
This example will walk you through creating a semantic search tool step by step, using Python and a popular pre-trained model for generating embeddings. Whether you’re new to the field or an experienced practitioner, this implementation will give you a practical understanding of how embeddings power smarter search systems.
Step 1: Setting Up Your Environment
Before diving in, ensure you have Python installed on your machine. We’ll use the sentence-transformers library, which offers state-of-the-art pre-trained models for generating embeddings.
Install the necessary library:
pip install sentence-transformersStep 2: Preparing the Data
To build a semantic search tool, we need a dataset of documents. Here’s a small example to get started:
documents = [
"Artificial Intelligence is fascinating.",
"Machine learning and deep learning are subsets of AI.",
"Natural Language Processing makes computers understand text.",
"Recommendation systems suggest content based on user preferences.",
"Vector embeddings power modern AI applications."
]These documents represent the knowledge base that our search tool will query.
Step 3: Generating Embeddings
Next, we use a pre-trained model from the sentence-transformers library to generate vector embeddings for these documents.
from sentence_transformers import SentenceTransformer
# Load a pre-trained embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Generate embeddings for the documents
doc_embeddings = model.encode(documents)
print("Document Embeddings Generated!")
Each document is now represented as a vector in a multi-dimensional embedding space.
Step 4: Building the Search Query Function
To perform a search, we need to compare the query’s embedding with the document embeddings. The most similar document will be our search result.
from sklearn.metrics.pairwise import cosine_similarity
def semantic_search(query, doc_embeddings, documents):
# Generate embedding for the query
query_embedding = model.encode([query])
# Compute cosine similarity between the query and document embeddings
similarities = cosine_similarity(query_embedding, doc_embeddings)
# Find the document with the highest similarity score
best_match_idx = similarities.argmax()
return documents[best_match_idx], similarities[0][best_match_idx]
# Example query
query = "What is AI?"
result, score = semantic_search(query, doc_embeddings, documents)
print(f"Best Match: {result} (Score: {score:.2f})")
Here, the function computes the cosine similarity between the query and each document. The document with the highest similarity score is returned as the best match.
Final Working Code: Semantic Search
The following script demonstrates the complete implementation of a semantic search tool. You can copy and paste it into your Python environment to test its functionality.
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
# Load a pre-trained embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Define the documents
documents = [
"Artificial Intelligence is fascinating.",
"Machine learning and deep learning are subsets of AI.",
"Natural Language Processing makes computers understand text.",
"Recommendation systems suggest content based on user preferences.",
"Vector embeddings power modern AI applications."
]
# Generate embeddings for the documents
doc_embeddings = model.encode(documents)
print("Document Embeddings Generated!")
# Define the semantic search function
def semantic_search(query, doc_embeddings, documents):
# Generate embedding for the query
query_embedding = model.encode([query])
# Compute cosine similarity between the query and document embeddings
similarities = cosine_similarity(query_embedding, doc_embeddings)
# Find the document with the highest similarity score
best_match_idx = similarities.argmax()
return documents[best_match_idx], similarities[0][best_match_idx]
# Example query
query = "What is AI?"
result, score = semantic_search(query, doc_embeddings, documents)
print(f"Best Match: {result} (Score: {score:.2f})")Step 5: Testing the Tool
Run the script and input your own queries to see how the semantic search performs. For example:
- Query: “What is machine learning?”
- Result: “Machine learning and deep learning are subsets of AI.”
Step 6: Scaling Up
This basic example can be scaled by:
- Using Larger Datasets: Replace the sample documents with a real-world dataset, such as product descriptions, FAQs, or academic papers.
- Indexing for Speed: Employ libraries like FAISS to handle large-scale similarity searches efficiently.
With this implementation, you’ve taken the first step toward building a semantic search tool. From here, you can explore advanced features like handling multi-modal data (text and images) or fine-tuning the embedding model for specific tasks.
Future Directions in Vector Embedding Technology
Discuss how advancements in AI, such as transformers and generative models, are pushing the boundaries of what embeddings can achieve. Explore potential applications in emerging fields like autonomous systems, AI ethics, and creative industries.
Challenges and Limitations
Acknowledge challenges in the development and implementation of vector embeddings. For instance:
- Scalability Issues: Handling large-scale datasets efficiently.
- Bias in Data: How embeddings may inadvertently capture and amplify biases present in training data.
- Interpretability: The difficulty of understanding what embeddings truly represent.
Case Study: Real-World Implementation
Delve into a detailed case study of an organization or project that successfully used vector embeddings to solve a problem. For example, describe how embeddings improved search relevance for a niche industry.
Hands-On Projects for Readers
Encourage engagement by outlining mini-projects readers can try, such as:
- Building a movie recommendation system.
- Creating a chatbot that uses embeddings for contextual responses.
- Implementing a custom embedding-based search engine for personal or business use.
Wrapping It Up
Vector embeddings are the silent engines driving some of the most transformative AI applications in our daily lives. From smarter searches to personalized recommendations, their potential is vast and far-reaching. As we’ve explored, the journey from understanding the basics to building your own implementations is not just a technical challenge—it’s a gateway to innovation.
Looking ahead, advancements in AI will continue to refine the power and precision of embeddings, opening doors to new applications in autonomous systems, creative industries, and beyond. However, challenges like scalability, bias, and interpretability remind us that responsible and ethical development is key.
The possibilities are limitless, and now it’s your turn to dive in. Whether it’s crafting a movie recommendation system or building a custom semantic search engine, the tools and concepts are within your reach. The future of AI is a collaborative effort—so why not start shaping it today?
Start building smarter solutions with us. Whether it’s your first AI project or the next big idea, we’re ready to help you succeed. Let’s connect!